AI News
Alibaba Researchers Propose VideoLLaMA 3: An Advanced Multimodal Foundation Model for Image and Video Understanding
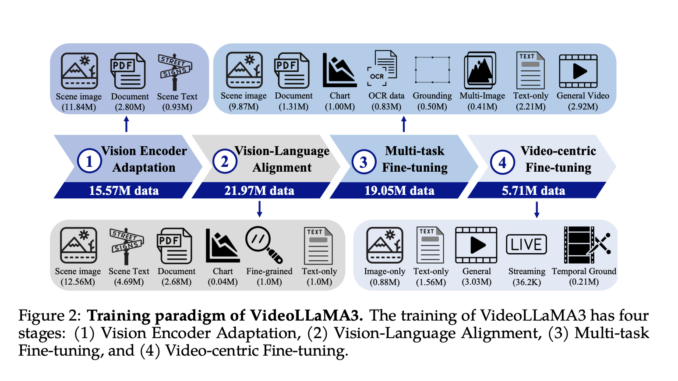
Advancements in multimodal intelligence depend on processing and understanding images and videos. Images can reveal static scenes by providing information regarding details such as objects, text, and spatial relationships. However, this comes at the cost […]








