AI News
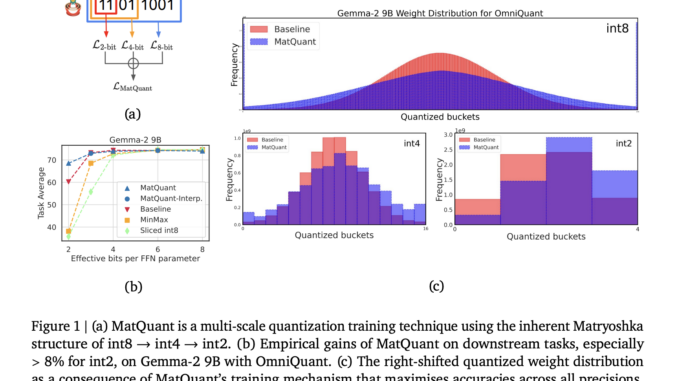
Google DeepMind Researchers Propose Matryoshka Quantization: A Technique to Enhance Deep Learning Efficiency by Optimizing Multi-Precision Models without Sacrificing Accuracy
Quantization is a crucial technique in deep learning for reducing computational costs and improving model efficiency. Large-scale language models demand significant processing power, which makes quantization essential for minimizing memory usage and enhancing inference speed. […]