AI News
VITA-1.5: A Multimodal Large Language Model that Integrates Vision, Language, and Speech Through a Carefully Designed Three-Stage Training Methodology
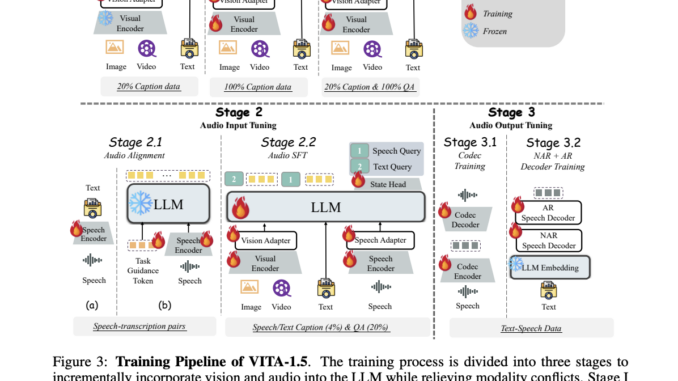
The development of multimodal large language models (MLLMs) has brought new opportunities in artificial intelligence. However, significant challenges persist in integrating visual, linguistic, and speech modalities. While many MLLMs perform well with vision and text, […]








